Chapter 1: Greenhouse Gase - The prime suspect#
Long-Term Development of CO2 and CH4 Concentrations#
Generation of plots based on the relevant Climate Indicators’ report.#
The ongoing climate change and the subsequent incease of earth’s temperature is a hot topic in recent years; a topic that has lately expanded from the purely scientific communities and now touches almost all aspects of our lives. There is much said about the role that the GreenHouse Gases (GHG) play in this climatic crisis. Let’s follow this tutorial and find out if and how the concentrations of two key GHG (carbon dioxide - CO2, and methane - CH4) changed in the last decades.
In this tutorial we will:
Search, download, and view data freely available in Climate Data Store.
Calculate global and regional monthly timeseries.
Mask the data and use spatiotemporal subsets for plotting.
View time series and analyse trends.
Create gridded plots and analyse spatial variations.
| Run the tutorial via free cloud platforms: |
|
 |
|
|---|
Section 1. Install & import the necessary packages.#
The first step for being able to analyse and plot the data is to download and import the necessary libraries for this tutorial. We categorized the libraries based on that they are used for: general libraries, libraries for data analysis, and plotting libraries.
# General libraries
from string import ascii_lowercase as ABC # String operations
import datetime # date
import calendar # date calculations
import zipfile # for unzipping data
import os # operating system interfaces library
import cdsapi # CDS API
import urllib3 # Disable warnings for data download via API
urllib3.disable_warnings()
# Libraries for working with multidimensional arrays
import numpy as np # for n-d arrays
import pandas as pd # for 2-d arrays (including metadata for the rows & columns)
import xarray as xr # for n-d arrays (including metadata for all the dimensions)
# Libraries for plotting and visualising data
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
import seaborn as sns
import cartopy.crs as ccrs
import cartopy.feature as cfeature
import cartopy.mpl.geoaxes
The below is for having a consistent plotting across all tutorials. It will NOT work in Google Colab or other cloud services, unless you include the file (available in the Github repository) in the cloud and in the same directory as this notebook, and use the correct path, e.g.
plt.style.use('copernicus.mplstyle').
plt.style.use('../copernicus.mplstyle') # use the predefined matplotlib style for consistent plotting across all tutorials
Section 2. Download data from CDS.#
Let’s create a folder were all the data will be stored.
dir_loc = 'data/' # assign folder for storing the downloaded data
os.makedirs(dir_loc, exist_ok=True) # create the folder if not available
Enter CDS API key
We will request data from the Climate Data Store (CDS) programmatically with the help of the CDS API. Let us make use of the option to manually set the CDS API credentials. First, you have to define two variables: URL and KEY which build together your CDS API key. The string of characters that make up your KEY includes your personal User ID and CDS API key. To obtain these, first register or login to the CDS (http://cds.climate.copernicus.eu), then visit https://cds.climate.copernicus.eu/api-how-to and copy the string of characters listed after “key:”. Replace the ######### below with that string.
# CDS key
cds_url = 'https://cds.climate.copernicus.eu/api/v2'
cds_key = '########' # please add your key here the format should be as {uid}:{api-key}
Get GHG data from the satellite products, that are available at CDS. In CDS a user can browse all available data from the search option, and once the selected dataset is identified, one can see from the download tab the exact API request. For example in this link you can see the satellite methane data. For this tutorial we used the options:
Processing level: Level 3
Variable: Column-averaged dry-air mixing ratios of methane (XCH4) and related variables
Version: 4.4
Format: zip
c = cdsapi.Client(url=cds_url, key=cds_key)
c.retrieve(
'satellite-methane',
{
'format': 'zip',
'processing_level': 'level_3',
'sensor_and_algorithm': 'merged_obs4mips',
'version': '4.4',
'variable': 'xch4',
},
f'{dir_loc}satellites_CH4.zip')
c.retrieve(
'satellite-carbon-dioxide',
{
'format': 'zip',
'processing_level': 'level_3',
'sensor_and_algorithm': 'merged_obs4mips',
'version': '4.4',
'variable': 'xco2',
},
f'{dir_loc}satellites_CO2.zip')
2023-06-24 20:35:51,245 INFO Welcome to the CDS
2023-06-24 20:35:51,246 INFO Sending request to https://cds.climate.copernicus.eu/api/v2/resources/satellite-methane
2023-06-24 20:35:51,829 INFO Request is completed
2023-06-24 20:35:51,830 INFO Downloading https://download-0012-clone.copernicus-climate.eu/cache-compute-0012/cache/data7/dataset-satellite-methane-9e933b79-0a27-4f67-bc8e-a998a1580be3.zip to data/satellites_CH4.zip (15.1M)
2023-06-24 20:36:02,142 INFO Download rate 1.5M/s
2023-06-24 20:36:02,380 INFO Welcome to the CDS
2023-06-24 20:36:02,381 INFO Sending request to https://cds.climate.copernicus.eu/api/v2/resources/satellite-carbon-dioxide
2023-06-24 20:36:03,012 INFO Downloading https://download-0021.copernicus-climate.eu/cache-compute-0021/cache/data5/dataset-satellite-carbon-dioxide-b104dd8a-ea1d-4b6d-b68d-32edda46a5f1.zip to data/satellites_CO2.zip (12.2M)
2023-06-24 20:36:20,484 INFO Download rate 717.3K/s
Result(content_length=12831918,content_type=application/zip,location=https://download-0021.copernicus-climate.eu/cache-compute-0021/cache/data5/dataset-satellite-carbon-dioxide-b104dd8a-ea1d-4b6d-b68d-32edda46a5f1.zip)
The data are downloaded in zip format. Let’s unzip them and rename them with an intuitive name.
# unzip the satellite data, rename the file and delete the original zip
for i_ghg in ['CO2', 'CH4']: # loop through both variables
with zipfile.ZipFile(f'{dir_loc}satellites_{i_ghg}.zip','r') as zip_ref:
zip_ref.extractall(dir_loc) # unzip file
source_file = '200301_202112-C3S-L3_GHG-GHG_PRODUCTS-MERGED-MERGED-OBS4MIPS-MERGED-v4.4.nc' # the name of the unzipped file
os.rename(f'{dir_loc}{source_file}', f'{dir_loc}satellites_{i_ghg}.nc') # rename to more intuitive name
os.remove(f'{dir_loc}satellites_{i_ghg}.zip') # delete original zip file
# read the data with xarray
co2_satellites = xr.open_dataset(f'{dir_loc}satellites_CO2.nc')
ch4_satellites = xr.open_dataset(f'{dir_loc}satellites_CH4.nc')
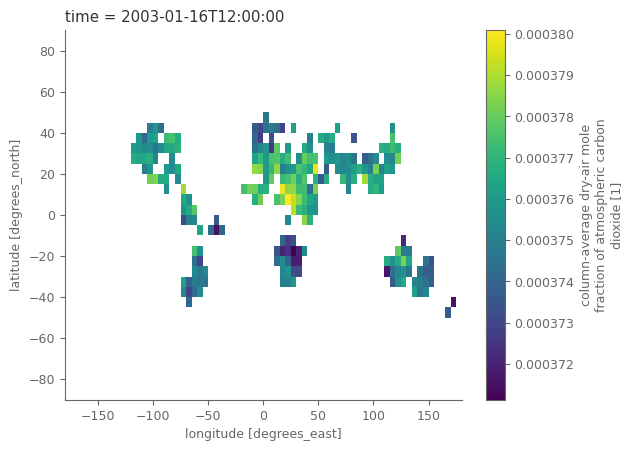
Let’s observe how the satellite data looks like. Notice that the grid is 5 degrees lot, lat, and that the time coordinate refers to the middle day of the relevant month. There are also a lot of different variables, including the CO2 values and standard deviations related to the uncertainty.
co2_satellites
<xarray.Dataset>
Dimensions: (time: 228, bnds: 2, lat: 36, lon: 72, pressure: 10)
Coordinates:
* time (time) datetime64[ns] 2003-01-16T12:00:00 ... 20...
* lat (lat) float64 -87.5 -82.5 -77.5 ... 77.5 82.5 87.5
* lon (lon) float64 -177.5 -172.5 -167.5 ... 172.5 177.5
Dimensions without coordinates: bnds, pressure
Data variables:
time_bnds (time, bnds) datetime64[ns] ...
lat_bnds (lat, bnds) float64 ...
lon_bnds (lon, bnds) float64 ...
pre (pressure) float64 ...
pre_bnds (pressure, bnds) float64 ...
land_fraction (lat, lon) float64 ...
xco2 (time, lat, lon) float32 ...
xco2_nobs (time, lat, lon) float64 ...
xco2_stderr (time, lat, lon) float32 ...
xco2_stddev (time, lat, lon) float32 ...
column_averaging_kernel (time, pressure, lat, lon) float32 ...
vmr_profile_co2_apriori (time, pressure, lat, lon) float32 ...
Attributes: (12/28)
activity_id: obs4MIPs
comment: Since long time, climate modellers use ensemble a...
contact: Maximilian Reuter (maximilian.reuter@iup.physik.u...
Conventions: CF-1.7 ODS-2.1
creation_date: 2022-07-10T09:25:22Z
data_specs_version: 2.1.0
... ...
source_version_number: v4.4
title: C3S XCO2 v4.4
tracking_id: ca42b88b-c774-4a16-9ad8-a49f9a4839fd
variable_id: xco2
variant_info: Best Estimate
variant_label: BENOTE:
The selected datasets have data up to 2021. For the ones interested in expanding the data with near-real time information, satellite measurements for the recent period are available here.
# "quick and dirty" plot of the data
co2_satellites['xco2'].isel(time=0).plot()
<matplotlib.collections.QuadMesh at 0x7f7321afb910>
Since we have a different variable for each GHG it is easier to combine them both in one variable.
# monthly sampled, spatially resolved GHG concentration in the atmosphere
concentration = xr.merge([co2_satellites['xco2'], ch4_satellites['xch4']]).to_array('ghg')
# associated standard errors
std_error = xr.merge([co2_satellites['xco2_stderr'], ch4_satellites['xch4_stderr']]).to_array('ghg')
std_error = std_error.assign_coords(ghg=['xco2', 'xch4'])
# associated land fraction; is the same for CO2 and CH4
land_fraction = co2_satellites['land_fraction']
is_land = land_fraction >= 0.5 # anything with land_fraction at least 50% is considered as land
is_land.name = 'is_land'
concentration.to_dataset('ghg') # for briefly checking the variable its better to see it as 'dataset' so that it's visually nicer
<xarray.Dataset>
Dimensions: (time: 228, lat: 36, lon: 72)
Coordinates:
* time (time) datetime64[ns] 2003-01-16T12:00:00 ... 2021-12-16T12:00:00
* lat (lat) float64 -87.5 -82.5 -77.5 -72.5 -67.5 ... 72.5 77.5 82.5 87.5
* lon (lon) float64 -177.5 -172.5 -167.5 -162.5 ... 167.5 172.5 177.5
Data variables:
xco2 (time, lat, lon) float32 nan nan nan nan nan ... nan nan nan nan
xch4 (time, lat, lon) float32 nan nan nan nan nan ... nan nan nan nan
Attributes:
standard_name: dry_atmosphere_mole_fraction_of_carbon_dioxide
long_name: column-average dry-air mole fraction of atmospheric carbo...
units: 1
cell_methods: time: mean
fill_value: 1e+20
comment: Satellite retrieved column-average dry-air mole fraction ...Clearly, after merging the attrs of the DataArray are not correct anymore, so let’s quickly adapt them:
concentration = concentration.assign_attrs({
'standard_name': 'dry_atmosphere_mole_fraction',
'long_name': 'column-average dry-air mole fraction',
'comment': 'Satellite retrieved column-average dry-air mole fraction'
})
# change temporal coordinates to refer to the start of the month
concentration = concentration.assign_coords( {'time': pd.to_datetime(concentration.time.dt.strftime('%Y%m01'))} ) # date at start of month
std_error = std_error.assign_coords( {'time': pd.to_datetime(std_error.time.dt.strftime('%Y%m01'))} )
concentration.time
<xarray.DataArray 'time' (time: 228)>
array(['2003-01-01T00:00:00.000000000', '2003-02-01T00:00:00.000000000',
'2003-03-01T00:00:00.000000000', ..., '2021-10-01T00:00:00.000000000',
'2021-11-01T00:00:00.000000000', '2021-12-01T00:00:00.000000000'],
dtype='datetime64[ns]')
Coordinates:
* time (time) datetime64[ns] 2003-01-01 2003-02-01 ... 2021-12-01Section 3. Calculate the GHG concentrations and growth rates#
We will calculate the monthly averages of global and regional GHG concentrations, as well as a 12-month temporally-smoothed global average for removing possible seasonal effects. As there are many steps in the process we will split this part in segments.
Note on values over ocean: water is a bad reflector in the short-wave infrared spectral region and requires a specific observation mode. Not all satellites that this dataset is based on have this specific mode which is why we consider values over land only in the following.
concentration = concentration.where(is_land)
std_error = std_error.where(is_land)
Focus on sub-polar regions#
In this particular example, we focus on latitudes between 60N and 60S.
region_of_interest = {
'Global': {'lat': slice(-60, 60), 'lon': slice(-180, 180)},
'Northern Hemishpere': {'lat': slice(0, 60), 'lon': slice(-180, 180)},
'Southern Hemisphere': {'lat': slice(-60, 0), 'lon': slice(-180, 180)}
}
Temporal smoothing#
Now we can define the auxiliary data needed for the temporal smoothing. Let’s be very precise and take into consideration that each month has different number of days.
smoothed_n_months = 12 # months used for the temporal smoothing
# get number of days for each month
years = concentration.time.dt.year.values
months = concentration.time.dt.month.values
days_month = [calendar.monthrange(yr, mn)[1] for yr, mn in zip(years, months)]
# temporal weights as xarray object (helps with automated alignment of the data for the calculations at the next steps)
weights_temporal = concentration.time.astype(int)*0+days_month
# weights should be changed to NaN for the cells that hava NaN in the relevant month
weights_temporal = weights_temporal.where(concentration.notnull())
It’s time to calculate the temporally smoothed data for each grid cell.
# rolling sum of the product of satellite measurements with the days per month
temp_smoothed = (concentration*weights_temporal).rolling(time=smoothed_n_months, min_periods=1, center=True).sum()
# min_periods=1 is needed, so that even if there is only 1 non-NaN value, there will be a result and not NaN
# divide with total number of days for getting the final weighted temporally-smoothed timeseries
temp_smoothed = temp_smoothed/weights_temporal.rolling(time=smoothed_n_months, min_periods=1, center=True).sum()
Spatial average#
Moving on with the spatial averaging now.
The data are projected in lat/lon system. This system does not have equal areas for all grid cells, but as we move closer to the poles, the areas of the cells are reducing. These differences can be accounted when weighting the cells with the cosine of their latitude.
weights_spatial = np.cos(np.deg2rad(concentration.lat)).clip(0, 1) # weights for satellite data
weights_spatial # the clip function above is for reassuring that all values will be between 0-1 regardless of the of machine's precision
<xarray.DataArray 'lat' (lat: 36)>
array([0.04361939, 0.13052619, 0.21643961, 0.3007058 , 0.38268343,
0.46174861, 0.53729961, 0.60876143, 0.67559021, 0.73727734,
0.79335334, 0.84339145, 0.88701083, 0.92387953, 0.95371695,
0.97629601, 0.99144486, 0.99904822, 0.99904822, 0.99144486,
0.97629601, 0.95371695, 0.92387953, 0.88701083, 0.84339145,
0.79335334, 0.73727734, 0.67559021, 0.60876143, 0.53729961,
0.46174861, 0.38268343, 0.3007058 , 0.21643961, 0.13052619,
0.04361939])
Coordinates:
* lat (lat) float64 -87.5 -82.5 -77.5 -72.5 -67.5 ... 72.5 77.5 82.5 87.5
Attributes:
standard_name: latitude
long_name: latitude
units: degrees_north
axis: Y
comment: latitude centerLet’s now combine both data (actual and temporally smoothed) in one dataset.
def area_weighted_spatial_average(data):
"""Calculate area-weighted spatial average of data
Parameters
----------
data : xarray.DataArray
DataArray with lat and lon coordinates
Returns
-------
xarray.DataArray
Area-weighted spatial average
"""
weights = np.cos(np.deg2rad(data.lat)).clip(0, 1) # weights
return data.weighted(weights).mean(['lat', 'lon'])
spatial_aver = []
for region, boundaries in region_of_interest.items():
conc = concentration.sel(**boundaries) # select the region of interest
temp = temp_smoothed.sel(**boundaries)
# spatial average of the raw data
sa = area_weighted_spatial_average(conc)
sa = sa.assign_coords({'type': 'raw'}).expand_dims('type')
# spatial average of the temporally smoothed data
sa_smoothed = area_weighted_spatial_average(temp)
sa_smoothed = sa_smoothed.assign_coords({'type': 'smoothed'}).expand_dims('type')
sa = xr.concat([sa, sa_smoothed], dim='type') # combine the monthly and smoothed data in 1 dataset
sa = sa.assign_coords({'region': region}) # add region as coordinate
spatial_aver.append(sa)
spatial_aver = xr.concat(spatial_aver, dim='region') # concatenate all regions in one xarray object
spatial_aver.to_dataset('ghg') # remember that we use 'dataset' object instead of 'dataarray' so that the information are visually nicer
<xarray.Dataset>
Dimensions: (region: 3, type: 2, time: 228)
Coordinates:
* time (time) datetime64[ns] 2003-01-01 2003-02-01 ... 2021-12-01
* type (type) <U8 'raw' 'smoothed'
* region (region) <U19 'Global' 'Northern Hemishpere' 'Southern Hemisphere'
Data variables:
xco2 (region, type, time) float64 0.0003758 0.0003765 ... 0.000414
xch4 (region, type, time) float64 1.749e-06 1.742e-06 ... 1.856e-06Maybe you noticed that we first did the temporal smoothing for each grid cell, and then performed the global average. This requires more computations from doing first the global average and then the temporal smoothing on the derived single global timeseries. Although the results are very similar (a to do task for the ones interested), the differences can considerably increase for datasets that have missing values at different grid cells each time step, as in our case with the satellite data.
Essentially, the most appropriate option from the two depends on the exact question posed by the user… Are we interested in temporally smoothed global average data, or in global average temporally smoothed gridded data?
Annnual growth rates#
The computation of growth rates and associated uncertainties is based on Buchwitz et al. (2018). The monthly sampled annual growth rates are computed as the difference between two monthly XCO2 values corresponding to the same month (e.g. January) but different years (e.g. 2004 and 2005). For example, the first data point is the difference of the April 2004 XCO2 value minus the April 2003 XCO2 value. The second data point corresponds to May 2004 minus May 2003, etc. The time difference between the monthly XCO2 pairs is always 1 year and the time assigned to each XCO2 difference is the time in the middle of that year. Therefore, the time series of growth rates starts 6 months later and ends 6 months earlier compared to the time series of XCO2 concentrations. Each XCO2 difference therefore corresponds to an estimate of the XCO2 annual growth rate and the position on the time axis corresponds to the middle of the corresponding 1-year time period.
As explained in Buchwitz et al. (2017)5 (see discussion of their Fig. 6.1.1.1), the underlying SCIAMACHY BESD v02.01.02 XCO2 data product apparently suffers from an approximately 1 ppm high bias in the first few months of 2003. As a consequence, these months should be removed for a less biased computation of the growth rates. For the sake of simplicity, we will refrain from doing so in this tutorial.
# accoridng to buchwitz 2018 the underlying SCIAMACHY BESD v02.01.02 XCO2 data product apparently suffers from an bias in the first 3 months of 2003
# xco2.loc[xco2.time.isin(xco2.isel(time=slice(0, 3)).time)] = np.nan
# monthly sampled annual growth rates
growth_rates = spatial_aver.sel(type='raw', drop=True).shift(time=-6) - spatial_aver.sel(type='raw', drop=True).shift(time=6)
growth_rates.to_dataset('ghg') # remember that we use 'dataset' object instead of 'dataarray' so that the information are visually nicer
<xarray.Dataset>
Dimensions: (region: 3, time: 228)
Coordinates:
* time (time) datetime64[ns] 2003-01-01 2003-02-01 ... 2021-12-01
* region (region) <U19 'Global' 'Northern Hemishpere' 'Southern Hemisphere'
Data variables:
xco2 (region, time) float64 nan nan nan nan nan ... nan nan nan nan nan
xch4 (region, time) float64 nan nan nan nan nan ... nan nan nan nan nanThe annual mean growth rates can be computed by averaging all the monthly sampled annual growth rates, which are located in the year of interest (e.g. 2003). For most years, 12 annual growth rate values are available for averaging but there are some exceptions. For example, for the year 2003 only six values are present and for the years 2014 and 2015 there are only 11 values, as no data are available for January 2015 due to issues with the GOSAT satellite.
# yearly sampled annual growth rates
mean_growth_rates = growth_rates.groupby('time.year').mean()
mean_growth_rates.to_dataset('ghg') # remember that we use 'dataset' object instead of 'dataarray' so that the information are visually nicer
<xarray.Dataset>
Dimensions: (region: 3, year: 19)
Coordinates:
* region (region) <U19 'Global' 'Northern Hemishpere' 'Southern Hemisphere'
* year (year) int64 2003 2004 2005 2006 2007 ... 2017 2018 2019 2020 2021
Data variables:
xco2 (region, year) float64 1.311e-06 1.584e-06 ... 1.898e-06 2.113e-06
xch4 (region, year) float64 1.91e-09 -1.203e-09 ... 1.441e-08 1.605e-08Uncertainty estimates of growth rates#
We can compute a 1σ uncertainty estimate for each of the monthly sampled annual growth rates following Buchwitz et al. (2018). They have been computed such that they reflect the following aspects:
the standard error of the XCO2 concentration values for each of the grid cells (
term1)the spatial variability of the XCO2 within the selected region (
term2)the temporal variability of the annual growth rates in the 1-year time interval, which corresponds to the annual growth rate (
term3), andthe number of months (
N) with data located in that 1-year time interval.
The 1σ uncertainties are then computed as $\( \sigma = \frac{term1 + term2 + term3}{3\sqrt{N}}. \)$
As noted by Buchwitz et al. (2018) the aim is to provide realistic error estimates. However, they acknowledge that the uncertainty estimates are not based on full error propagation, which would be difficult, especially due to unknown or not well enough known systematic errors and error correlations. The reported uncertainty estimates should therefore be interpreted as error indications rather than fully rigorous error estimates.
def compute_uncertainty(standard_error, concentration, growth_rates):
wghts = np.cos(np.deg2rad(concentration.lat)).clip(0, 1) # weights for subselection
# uncertainty estimation of growth rates
term1 = standard_error.weighted(wghts).mean(('lat', 'lon'))
term2 = concentration.weighted(wghts).std(('lat', 'lon'))
term3 = growth_rates.rolling({'time': 12}, center=True, min_periods=2).std()
N = growth_rates.notnull().rolling({'time': 12}, center=True, min_periods=1).sum()
# 1 sigma uncertainty
uncertainty = (term1 + term2 + term3) / 3 / np.sqrt(N)
return uncertainty
uncertainty = []
for region, coords in region_of_interest.items():
conc = concentration.sel(**coords)
se = std_error.sel(**coords)
gr = growth_rates.sel(region=region)
sigma = compute_uncertainty(se, conc, gr)
sigma = sigma.assign_coords({'region': region})
uncertainty.append(sigma)
uncertainty = xr.concat(uncertainty, dim='region')
uncertainty.to_dataset('ghg') # remember that we use 'dataset' object instead of 'dataarray' so that the information are visually nicer
<xarray.Dataset>
Dimensions: (region: 3, time: 228)
Coordinates:
* time (time) datetime64[ns] 2003-01-01 2003-02-01 ... 2021-12-01
* region (region) <U19 'Global' 'Northern Hemishpere' 'Southern Hemisphere'
Data variables:
xco2 (region, time) float64 nan nan 7.448e-07 ... 4.668e-07 nan
xch4 (region, time) float64 nan nan 9.249e-09 ... 9.418e-09 nanThe uncertainty of the annual mean growth rate has been computed by averaging the uncertainties assigned to each of the monthly sampled annual growth rates scaled with a factor, which depends on the number of months (\(N'\)=number_months_available) available for averaging. This factor is the square root of \(12/N'\). It ensures that the larger the uncertainty, the fewer data points there are available for averaging.
number_months_available = uncertainty.notnull().groupby('time.year').sum()
mean_uncertainty = uncertainty.groupby('time.year').mean() * np.sqrt(12 / number_months_available)
(1e6*mean_uncertainty).sel(ghg='xco2').round(2) # show the uncertainties of XCO2 in ppm
<xarray.DataArray (region: 3, year: 19)>
array([[0.5 , 0.28, 0.27, 0.27, 0.25, 0.28, 0.31, 0.3 , 0.32, 0.31, 0.32,
0.31, 0.33, 0.3 , 0.3 , 0.3 , 0.31, 0.31, 0.47],
[0.45, 0.26, 0.24, 0.24, 0.23, 0.25, 0.28, 0.27, 0.28, 0.28, 0.28,
0.28, 0.3 , 0.27, 0.26, 0.26, 0.27, 0.27, 0.42],
[0.36, 0.2 , 0.19, 0.2 , 0.2 , 0.22, 0.21, 0.21, 0.2 , 0.2 , 0.2 ,
0.2 , 0.22, 0.22, 0.2 , 0.19, 0.23, 0.22, 0.33]])
Coordinates:
ghg <U4 'xco2'
* region (region) <U19 'Global' 'Northern Hemishpere' 'Southern Hemisphere'
* year (year) int64 2003 2004 2005 2006 2007 ... 2017 2018 2019 2020 2021Overall, the uncertainty estimate is quite conservative, as it does not assume that errors improve upon averaging. As a result of this procedure, the error bar of the year 2003 growth rate is quite large. This is because the monthly sampled annual growth rate varies significantly in 2003 and because only \(N=6\) data points are available for averaging in 2003. In contrast, the year 2005 growth rate uncertainty is much smaller, because the growth rates vary less during 2005 and because \(N=12\) data points are available for averaging.
Plot the evolution of GHG concentration and growth rates.#
Generate auxiliary data used for plotting.
prop_cycle_clrs = plt.rcParams['axes.prop_cycle'].by_key()['color']
aux_var = {
'xco2': {
'name':'Atmospheric carbon dioxide', 'units': 'ppm', 'unit_factor': 1e6, # unit factor because data are not in the unit of interest
'shortname': r'CO$_{2}$', 'color': prop_cycle_clrs[0], 'ylim': (370, 420), 'ylim_growth': (0, 4)
},
'xch4': {
'name':'Atmospheric methane', 'units': 'ppb', 'unit_factor': 1e9,
'shortname': r'CH$_{4}$', 'color': prop_cycle_clrs[1], 'ylim': (1725, 1950), 'ylim_growth': (-5, 25)
},
}
Create plotting functions for the timeseries and the barplot.
def create_summary_plot(ghg_conc, growth_rates, uncertainty, aux_var):
'Create function for plotting timeseries (as lines)'
ghg_conc = ghg_conc.copy()
growth_rates = growth_rates.copy()
uncertainty = uncertainty.copy()
# create the figure layout and the subplots
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
y_label0 = f'A | Column-averaged {aux_var["shortname"]}'
y_label1 = 'B | Annual growth rate'
# multiply with unit factor
ghg_conc *= aux_var['unit_factor']
growth_rates *= aux_var['unit_factor']
uncertainty *= aux_var['unit_factor']
# GHG concentrations
ghg_conc.plot.line(ax=axes[0], x='time', add_legend=True, hue='type', label=['Raw data', 'Smoothed'])
# add legend in the center right of the plot
axes[0].legend(loc='center right', ncol=1, frameon=False)
# GHG growth rates
axes[1].bar(growth_rates.year, growth_rates, yerr=uncertainty, ecolor='grey')
# add a dashed line at zero
axes[1].axhline(0, color='grey', linestyle='--')
# format the axes
[i_ax.set_xlabel('') for i_ax in axes]
[i_ax.set_ylabel('') for i_ax in axes]
axes[0].set_title(y_label0)
axes[1].set_title(y_label1)
# add unit as text below title in smaller font
axes[0].text(0., .98, f' in {aux_var["units"]}', transform=axes[0].transAxes, fontsize=10, ha='left', style='italic')
axes[1].text(0., .98, f' in {aux_var["units"]}/yr', transform=axes[1].transAxes, fontsize=10, ha='left', style='italic')
start_date = datetime.datetime(2002, 1, 1)
end_date = datetime.datetime(ghg_conc.time.dt.year.values[-1] + 2, 1, 1)
axes[0].set_xlim(start_date, end_date)
axes[1].set_xlim(start_date.year, end_date.year)
# get xticks as datetime objects every second year
xticks = [datetime.datetime(yr, 1, 1) for yr in range(start_date.year, end_date.year, 2)]
axes[0].set_xticks(xticks)
axes[1].set_xticks([tick.year for tick in xticks])
axes[0].set_xticklabels([tick.strftime('%Y') for tick in xticks], rotation=0)
axes[1].set_xticklabels([tick.strftime('%Y') for tick in xticks], rotation=0)
# define the limits of the y axis
axes[0].set_ylim(aux_var['ylim'])
axes[1].set_ylim(aux_var['ylim_growth'])
for ax in axes:
sns.despine(ax=ax, trim=True, offset=10) # trimming the y and x axis to be visible only from the fist till the last tick
# add a small map showing the spatial domain that was used to derive the timeseries. This will be done with the help of inset_axes
axins = inset_axes(axes[0], width="30%", height="30%", loc="lower right",
axes_class=cartopy.mpl.geoaxes.GeoAxes,
axes_kwargs=dict(projection=ccrs.EqualEarth()))
axins.add_feature(cfeature.LAND, color='.6', lw=.5) # add land object
region = ghg_conc.region.values.tolist()
x0, y0 = region_of_interest[region]['lon'].start, region_of_interest[region]['lat'].start
x1, y1 = region_of_interest[region]['lon'].stop, region_of_interest[region]['lat'].stop
x = [x0, x1, x1, x0, x0]
y = [y0, y0, y1, y1, y0]
axins.fill(x, y, transform=ccrs.PlateCarree(), alpha=0.5) # color the area used for the analysis
axins.set_global()
fig.subplots_adjust(hspace=.3) # adjust the space between the subplots
return fig, axes
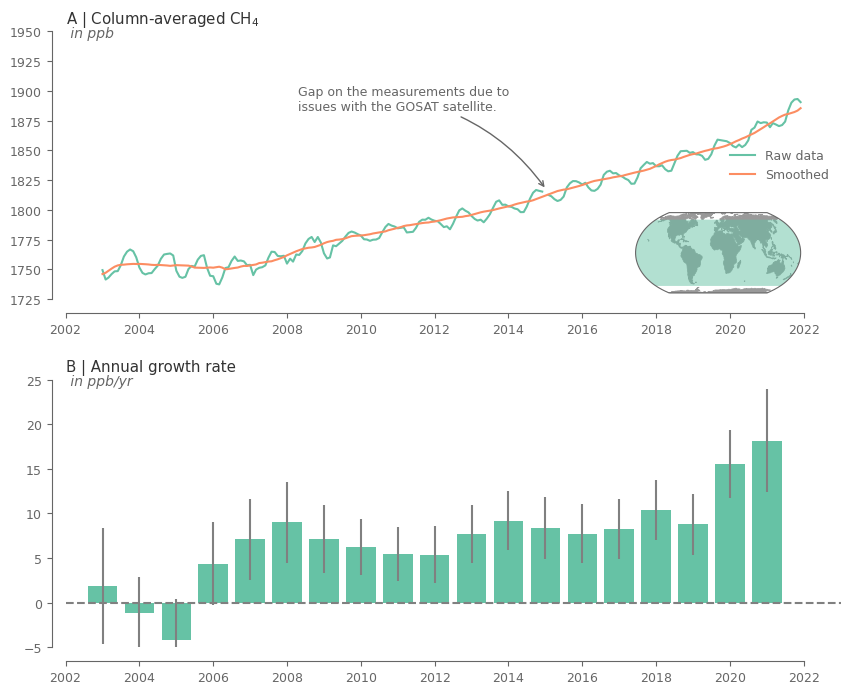
Create the plot for CH4.
variable = 'xch4'
region = 'Global'
fig, axes = create_summary_plot(
spatial_aver.sel(ghg=variable, region=region),
mean_growth_rates.sel(ghg=variable, region=region),
mean_uncertainty.sel(ghg=variable, region=region),
aux_var[variable]
)
# add text highlighting the gap on the data
axes[0].annotate(
'Gap on the measurements due to \nissues with the GOSAT satellite.',
xy=(pd.to_datetime('20150110'), 1817),
xytext=(0.3, 0.8),
textcoords=axes[0].transAxes,
ha='left', va='top',
arrowprops=dict(arrowstyle='->', color='.4', connectionstyle='arc3,rad=-0.2')
)
plt.show()
Create the plot for CO2.
One important climate milestone for our combat against climate change was the 400ppm for CO2 concentrations. A milestone that we unfortunatelly exceeded some years ago. Let’s find out when exactly did this happen for the first time, and add this information to the relevant plot.
# get the date the CO2 concentrations exceed a certain threshold for the first time
thrs = 400e-6 # threshold for CO2 concentration (400 ppm)
is_above_thrs = spatial_aver.sel(ghg='xco2', type='raw', region='Global') >= 400e-6 # check which timeslices exceed the threshold
idx_first_time_step_above_thrs = is_above_thrs.argmax(dim='time', skipna=True) # first the index of the first timeslice that threshold was exceeded
first_time_thrs = concentration.time.isel(time=idx_first_time_step_above_thrs).values # get the actual timeslice of 1st thresholfd exceedance
first_time_thrs = pd.to_datetime(first_time_thrs)
first_time_thrs
Timestamp('2015-03-01 00:00:00')
variable = 'xco2'
region = 'Global'
fig, axes = create_summary_plot(
spatial_aver.sel(ghg=variable, region=region),
mean_growth_rates.sel(ghg=variable, region=region),
mean_uncertainty.sel(ghg=variable, region=region),
aux_var[variable]
)
# add text about the 400ppm in case of CO2 with an arrow pointing to the maximum value
desc = 'In ' + first_time_thrs.strftime('%B %Y')
desc += ', atmospheric CO$_2$ concentrations \nsurpassed 400 ppm, a milestone unseen in \nover 800,000 years.'
axes[0].annotate(
desc,
xy=(first_time_thrs, thrs * 1e6),
xytext=(0.05, 0.8),
color='red',
textcoords=axes[0].transAxes,
ha='left', va='top',
arrowprops=dict(arrowstyle='->', color='red', connectionstyle='arc3,rad=-0.2')
)
plt.show()
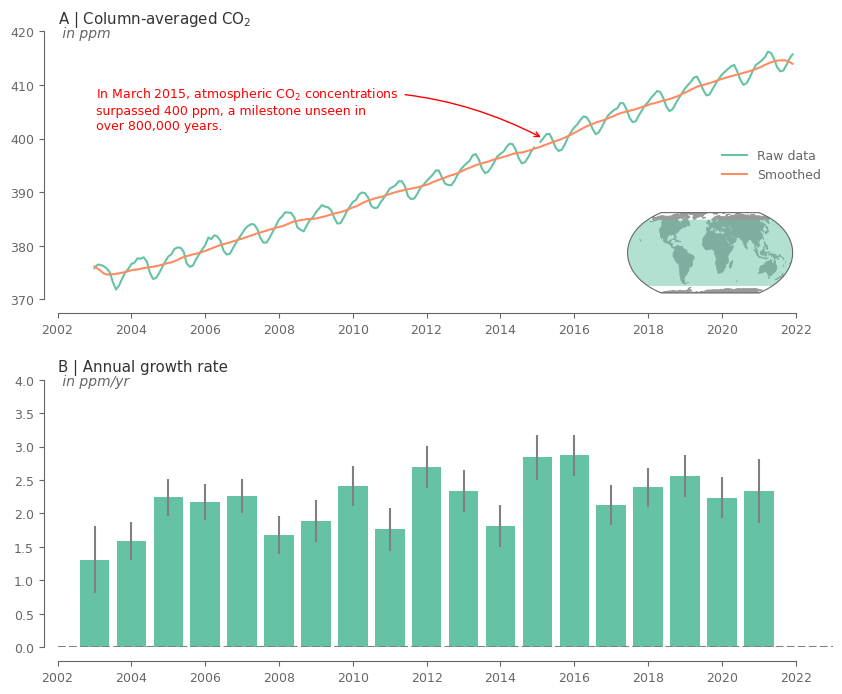
The above plots show a clear increasing trend in the concentrations of the GHG over the entire record. Moreover, it can be noticed that there is an evident seasonality for both GHG.
The rate of increase is quite varying across the years. Note that for the first and last year the results are not that reliable because there are only 6 months used in the analysis.
Comparing CO2 with CH4#
So far we have seen that there is indeed an increasing trend for both variables, while both of them have differences in the seasonal cycle and the annual growth rate.
Let’s now compare the behaviour across both variables. Since the values are of substantially different magnitude, we first need to normalize the data for being able to plot them on same plot.
Here we will use a simple normalization based on global mean and standard deviation. For the ones interested further, there is a small appendix demonstrating why considering anomalies based on monthly climatology, a method commonly used for other environmental variables, is not the best option in our case.
spatial_aver_norm = (spatial_aver-spatial_aver.mean('time'))/spatial_aver.std('time') # normalize the data
fig, ax = plt.subplots(1, 1, figsize=(9, 4))
spatial_aver_norm.sel(region='Global', type='raw').plot.line(ax=ax, x='time', hue='ghg', add_legend=True,
label=[aux_var[i]['shortname'] for i in spatial_aver_norm.ghg.values])
ax.legend()
ax.axhline(0, color='k', ls='--', lw=0.5)
ax.set_ylabel('Standardized anomalies')
ax.set_title('Monthly anomalies of GHG')
sns.despine(ax=ax, trim=True, offset=10) # trimming the y and x axis to be visible only from the fist till the last tick
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y')) # formatting is needed cause the above line breaks the time fo
plt.show()
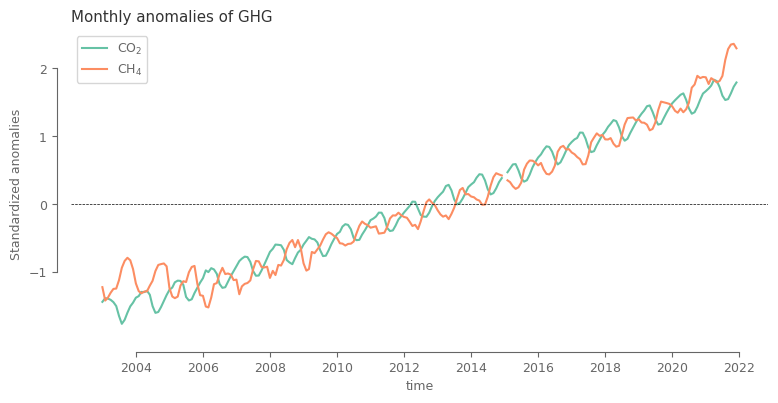
After the simple normalization it can be noted that the main difference between the two variables lie in the seasonal cycle, which is shifted.
Regional spatial averages#
The above analysis covers a large part of the globe, which does not give us the opportunity to access spatial differences. For this part of the GHG analysis, let’s visualize the hemispheric average values and understand how the concentrations evolve in the northern vs southern hemisphere.
fig, axes = plt.subplots(2, 1, figsize=(10, 9))
(1e6*spatial_aver).sel(ghg='xco2', type='raw').plot.line(ax=axes[0], x='time', hue='region', add_legend=True, label=spatial_aver.region.values)
(1e9*spatial_aver).sel(ghg='xch4', type='raw').plot.line(ax=axes[1], x='time', hue='region', add_legend=False)
axes[0].legend(loc='lower right')
for ax, var in zip(axes, ['xco2', 'xch4']):
y_label = f'A | Column-averaged {aux_var[var]["shortname"]}'
ax.set_title(y_label)
ax.text(0., .96, f' in {aux_var[var]["units"]}', transform=ax.transAxes, fontsize=10, ha='left', style='italic')
ax.set_xlim(datetime.datetime(2002, 1, 1), datetime.datetime(2022, 1, 1))
sns.despine(ax=ax, trim=True, offset=10)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y'))
fig.subplots_adjust(hspace=.3)
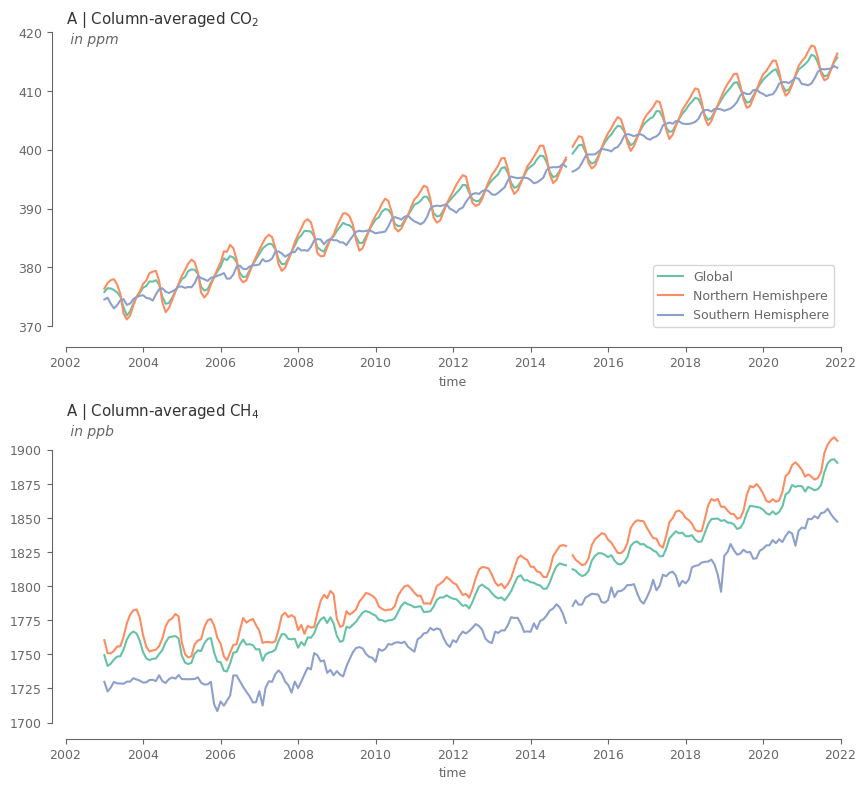
The methane (CH4) has a clear differentiation in the concentrations between the two hemispheres. CO2 shows no seasonality for the southern hemisphere. Can it be because we only use land, and land mass in the southern hemisphere is substantially smaller compared to the northern?
For both variables the northern hemisphere has the most impact in defining the global mean. What could be possible reasons for that? The larger land mass of northern hemisphere? Or maybe the fact that most of the global population and industrial activities lie in that hemisphere?
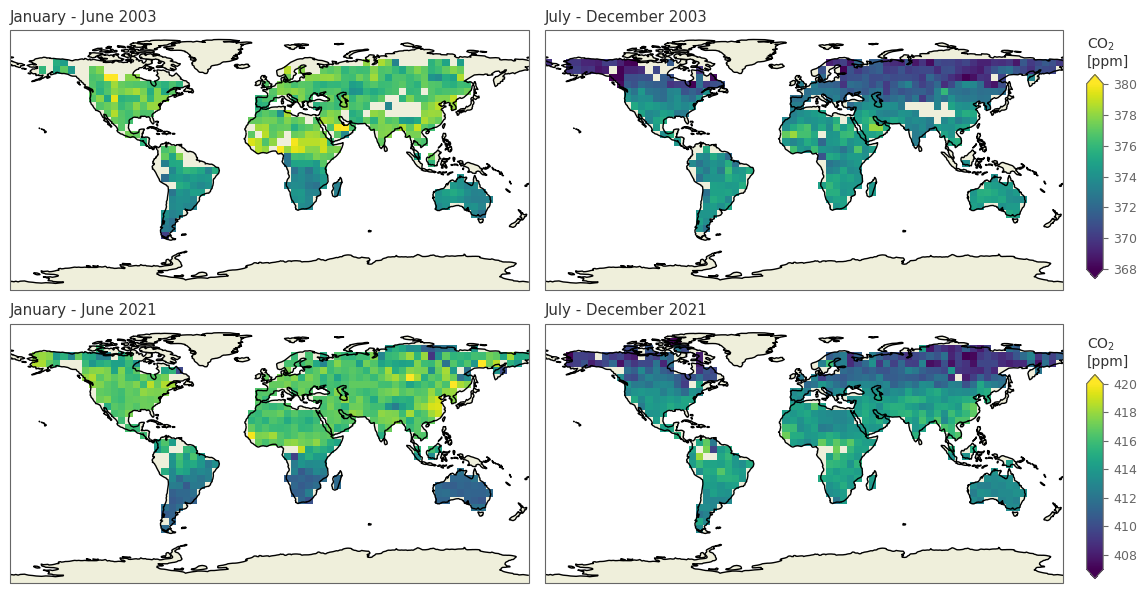
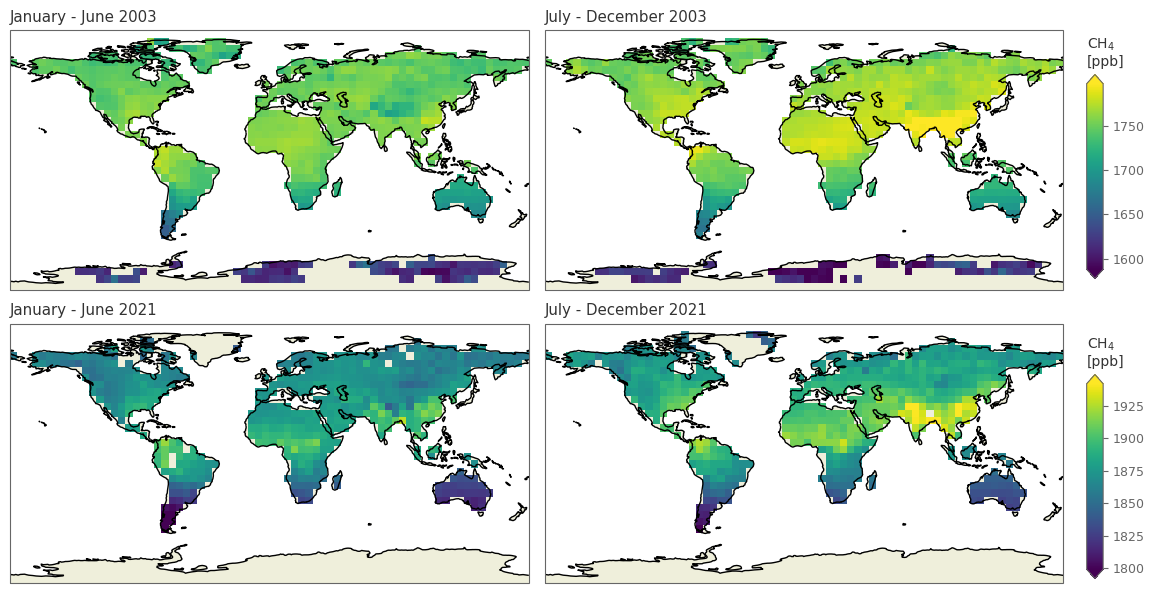
The differences are already visible in the hemispheric averages. What about the actual grid cells? Let’s find out…
# get the weights for the temporal smoothing based on the total number of days per month
years = concentration.time.dt.year.values
months = concentration.time.dt.month.values
days_month = [calendar.monthrange(yr, mn)[1] for yr, mn in zip(years, months)]
weights_temporal = concentration.time.astype(int)*0+days_month # temporal weights as xarray object (helps for automatic arrangements later)
# weights should be changed to NaN for the cells that hava NaN in the measurement
weights_temporal = weights_temporal.where(concentration.notnull()).fillna(0)
# created temporally-smoothed timeseries. Note that center=False this time, so the value refers to the 6-month period ending at the date
temp_smoothed = (concentration*weights_temporal).rolling(time=6, min_periods=1, center=False).sum()
temp_smoothed /= weights_temporal.rolling(time=6, min_periods=1, center=False).sum()
Define the function for plotting the spatial data for selected variable and 4 dates, with the first 2 referring to a year in the early periods and the last 2 to a more recent year.
def spatial_plot(selected_dates, selected_variable='xco2'):
"""
Inputs:
selected_dates: a list with 4 dates
selected_variable: "xco2" (default) or "xch4"
"""
data_used = temp_smoothed.sel(time=selected_dates, ghg=selected_variable).copy()
data_used *= aux_var[selected_variable]['unit_factor'] # multiply with unit factor for getting correct units
# get min/max values for the colorbars for the early and late subsets
early_dates_data = data_used.sel(time=selected_dates[:2]) # get subset of early dates
min_early = np.floor(early_dates_data.quantile(.01).values) # find min based on 1st Percentile
max_early = np.ceil(early_dates_data.quantile(.99).values) # find max based on 99th Percentile
late_dates_data = data_used.sel(time=selected_dates[2:])
min_late = np.floor(late_dates_data.quantile(.005).values)
max_late = np.ceil(late_dates_data.quantile(.995).values)
# define the figure
fig, ax = plt.subplots(2, 2, subplot_kw={'projection': ccrs.PlateCarree()}, figsize=(11, 6))
ax = ax.flatten()
for i, i_ax in enumerate(ax): # loop through the 4 axes, plot the data, and add background info (Land, Coastline)
if i<=1:
values_early = data_used.sel(time=selected_dates[i]) # get the subset to be plotted
plot_early = values_early.plot(ax=i_ax, add_colorbar=False, robust=True, vmin=min_early, vmax=max_early, extend='both') # plot
else:
values_late = data_used.sel(time=selected_dates[i])
plot_late = values_late.plot(ax=i_ax, add_colorbar=False, robust=True, vmin=min_late, vmax=max_late, extend='both')
i_ax.add_feature(cfeature.LAND) # add land
i_ax.add_feature(cfeature.COASTLINE) # add coastline
# add title
start_month = (pd.to_datetime(selected_dates[i])-pd.DateOffset(months=5)).strftime("%B") # get start month
end_month = pd.to_datetime(selected_dates[i])
i_ax.set_title(end_month.strftime(f'{start_month} - %B %Y')) # add the final title
# colorbar of early dates
fig.subplots_adjust(right=1)
cbar_ax_early = fig.add_axes([1, 0.53, 0.015, 0.34]) # define where the new axis for the colorbar will be added and specify its dimensions
fig.colorbar(plot_early, cax=cbar_ax_early, extend='both') # add the colorbar
cbar_ax_early.set_title(f"{aux_var[selected_variable]['shortname']}\n[{aux_var[selected_variable]['units']}]", size=10) # add title
# colorbar of late dates
fig.subplots_adjust(right=1)
cbar_ax_late = fig.add_axes([1, 0.03, 0.015, 0.34])
fig.colorbar(plot_late, cax=cbar_ax_late, extend='both')
cbar_ax_late.set_title(f"{aux_var[selected_variable]['shortname']}\n[{aux_var[selected_variable]['units']}]", size=10)
fig.tight_layout()
plt.show()
spatial_plot(['20030601', '20031201', '20210601', '20211201'], 'xco2')
/tmp/ipykernel_17869/988431502.py:52: UserWarning: This figure includes Axes that are not compatible with tight_layout, so results might be incorrect.
fig.tight_layout()
spatial_plot(['20030601', '20031201', '20210601', '20211201'], 'xch4')
/tmp/ipykernel_17869/988431502.py:52: UserWarning: This figure includes Axes that are not compatible with tight_layout, so results might be incorrect.
fig.tight_layout()
SUMMARY:
In this tutorial we analysed the concentrations of two Greenhouse Gases (GHG), in particular the carbon dioxide (CO2), and the methane (CH4). We used data for the years 2003-2021 based on satellite measurements.
The data showed that both GHG have a systematicly increasing trend of similar slope. This trend is a very alarming feature and as a lot of research has shown, it is the main cause of the ongoing climate change. CO2 and CH4 have a seasonal cycle which is slightly shifted, while there are substantial differences in the concentrations between the two hemispheres, especially so for the CH4.
Section 4. Useful links#
For the ones interested in finding out more about GHG, please find below some links for relevant articles and visualizations:
Global Monitorin Laboratory from NOAA, with a lot of information, relevant plots, and raw data that can be freely donwloaded.
Lashof, D., Ahuja, D. Relative contributions of greenhouse gas emissions to global warming. Nature 344, 529–531 (1990). https://doi.org/10.1038/344529a0
Buchwitz, M., Reuter, M., Schneising, O., Noël, S., Gier, B., Bovensmann, H., Burrows, J. P., Boesch, H., Anand, J., Parker, R. J., Somkuti, P., Detmers, R. G., Hasekamp, O. P., Aben, I., Butz, A., Kuze, A., Suto, H., Yoshida, Y., Crisp, D., and O’Dell, C.: Computation and analysis of atmospheric carbon dioxide annual mean growth rates from satellite observations during 2003–2016, Atmos. Chem. Phys., 18, 17355–17370 (2018), https://doi.org/10.5194/acp-18-17355-2018
Buchwitz, M., Dils, B., Boesch, H., Brunner, D., Butz, A., Crevoisier, C., Detmers, R., Frankenberg, C., Hasekamp, O., Hewson, W., Laeng, A., Noël, S., Notholt, J., Parker, R., Reuter, M., Schneising, O., Somkuti, P., Sundström, A.-M., and De Wachter, E.: ESA Climate Change Initiative (CCI) Product Validation and Intercomparison Report (PVIR) for the Essential Climate Variable (ECV) Greenhouse Gases (GHG) for data set Climate Research Data Package No. 4 (CRDP#4), Technical Report, version 5, available at: http://www.esa-ghg-cci.org/?q=webfm_send/352, 253 pp. (2017)
Appendix: Monthly climatology of the variables#
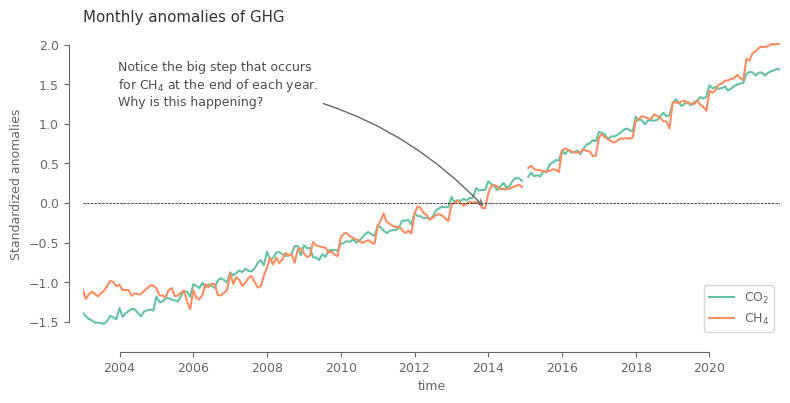
As we stated previously, we only used global mean and standard deviation for comparing both variables, and we did not use monthly climatology. Let’s see how the monthly climatology looks like, and why using it is not the best approach.
# what is normally done assuming a 'stationary' behaviour of the variable
climatology_mean = concentration.groupby('time.month').mean('time') # climatological mean for each month
climatology_std = concentration.groupby('time.month').std('time') # climatological standard deviation for each month
anomalies = (concentration.groupby('time.month') - climatology_mean) # anomalies after removing mean
anomalies = anomalies.groupby('time.month')/climatology_std # final anomalies after dividing with standard deviation
anomalies = area_weighted_spatial_average(anomalies.sel(lat=slice(-60, 60))) # get global average
fig, ax = plt.subplots(1, 1, figsize=(9, 4))
anomalies.plot.line(x='time', ax=ax, label=[aux_var[i]['shortname'] for i in spatial_aver_norm.ghg.values])
ax.legend()
ax.axhline(0, color='k', ls='--', lw=0.5)
ax.set_xlim(anomalies.time.values[0], anomalies.time.values[-1])
sns.move_legend(ax, loc='lower right')
sns.despine(ax=ax, trim=True, offset=10)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y'))
ax.set_title('Monthly anomalies of GHG')
ax.set_ylabel('Standardized anomalies')
date_annotate = pd.to_datetime('201312', format='%Y%m')
ax.annotate(
'Notice the big step that occurs \nfor CH$_4$ at the end of each year.\nWhy is this happening?',
xy=(date_annotate, anomalies.sel(ghg='xch4', time=date_annotate).values),
xytext=(0.05, 0.9),
textcoords=ax.transAxes,
ha='left', va='top', color='.3',
arrowprops=dict(arrowstyle='->', color='.4', connectionstyle='arc3,rad=-0.2')
)
plt.show()
Plot the monthly climatology (global average ) to understand if the issue is related to that step.
clim_spatial = climatology_mean.sel(lat=slice(-60, 60)).weighted(np.cos(np.deg2rad(climatology_mean.lat)).clip(0, 1)).mean(['lat', 'lon'])
fig, ax = plt.subplots(2, 1, figsize=(10, 6))
for i, j in enumerate(clim_spatial.ghg.values):
ax[i].plot(clim_spatial.month.values, clim_spatial.sel(ghg=j).values*aux_var[j]['unit_factor'])
ax[i].set_xlim(1, 13)
ax[i].set_title(f'({ABC[i]}) '+ aux_var[j]['name'] + ' (' + aux_var[j]['shortname'] + ')')
ax[i].set_ylabel('Colunn-averaged '+ aux_var[j]['shortname'] + ' [' + aux_var[j]['units'] + ']')
sns.despine(ax=ax[i], trim=True) # trimming the y and x axis to be visible only from the fist till the last tick
fig.subplots_adjust(hspace=.3)
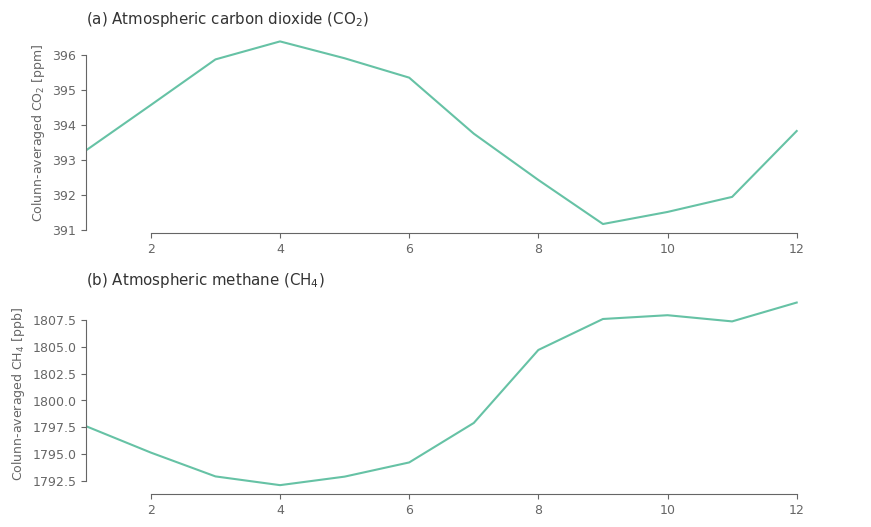
Maybe its more useful to present the results in polar coordinates, since from a climatological point of view the months follow a circular behaviour with December being similar to January.
fig, ax = plt.subplots(1, 2, figsize=(10, 10), subplot_kw={'projection': 'polar'})
for i, j in enumerate(clim_spatial.ghg.values):
yy_values = clim_spatial.sel(ghg=j).values*aux_var[j]['unit_factor'] # get the values and multiply with the unit factor
ax[i].plot( (clim_spatial.month.values)/12*2*np.pi, yy_values, linewidth=5 ) # plot the line
# color the graph based on y value for easily differentiating between the magnitudes for the months
segments = np.linspace(np.array(yy_values).min()*1, np.array(yy_values).max()*1., 5)
for seg_min, seg_max, i_alpha in zip(segments[:-1], segments[1:], np.arange(0.25, 1.01, .25)):
ax[i].fill_between(x=np.linspace(0, 2*np.pi, 360), y1=seg_max, y2=seg_min, color='.4', alpha=i_alpha)
ax[i].set_ylim(np.array(yy_values).min()*1, np.array(yy_values).max()*1.)
ax[i].set_xticks((clim_spatial.month.values)/12*2*np.pi)
ax[i].set_xticklabels(['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'])
ax[i].set_yticks(segments[::2], labels=np.round(segments, 1)[::2])
ax[i].set_axisbelow(False) # otherwise the green line hiddes the yticks (red values)
ax[i].tick_params(axis='y', colors='red', size=14, zorder=10)
ax[i].set_title(f'({ABC[i]}) '+ aux_var[j]['name'] + ' (' + aux_var[j]['shortname'] + ')')
ax[i].yaxis.set_label_coords(-0.2, 1)
ax[i].set_ylabel('Colunn-averaged '+ aux_var[j]['shortname'] + ' [' + aux_var[j]['units'] + ']', color='red')
fig.subplots_adjust(wspace=1)
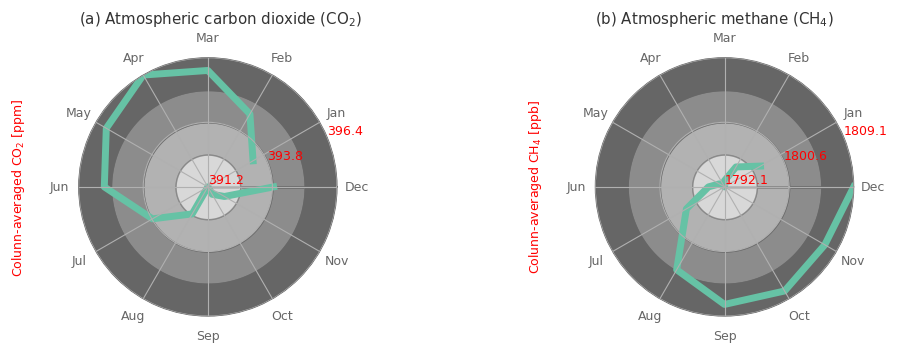
Notice the difference in the values between January mean state and December mean state for both GHG, especially so for CH4. This indicates that on average just in the course of 1 single year there is already a substantial increase in the concentrations, that do alter the expected seasonal cycle, as we normally would see the Jan and Dec values being very very close.
Because of this substantial reduction in the mean state of January compared to December we see the high jump for every January, as the climatological mean is small, thus the anomalies get large.
Therefore, in order to get the anomalies in a robust way, we should not only remove the seasonal cycle, but also detrend the data, as this dataset is highly non-stationary!